

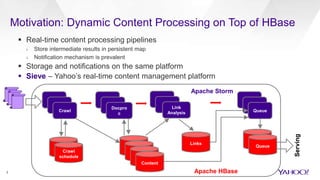




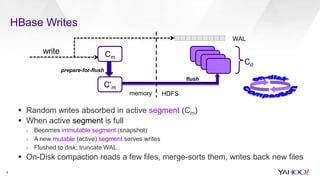
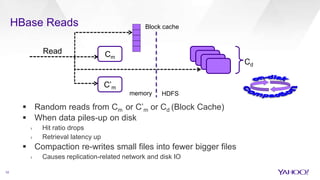
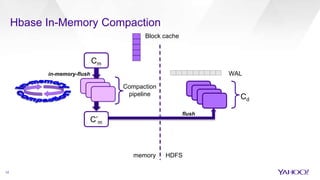
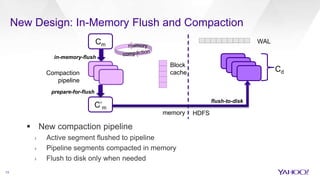
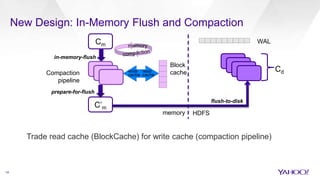
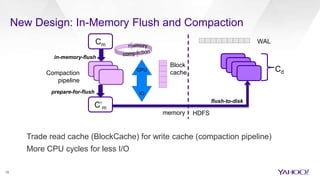


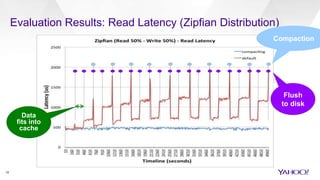
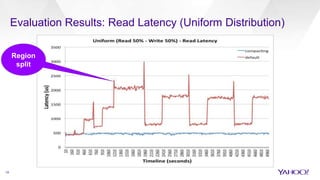
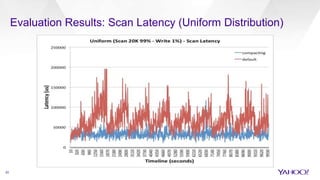

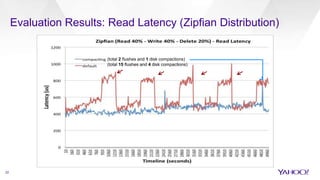
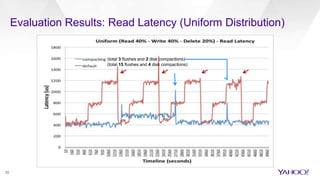
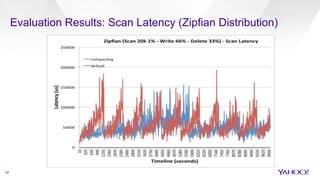

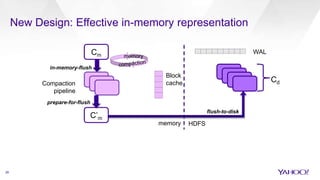
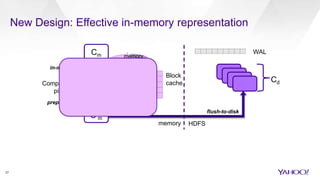
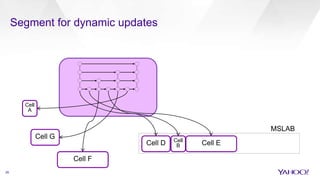

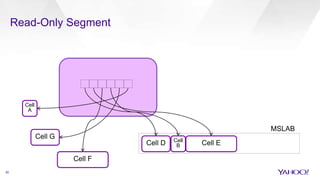
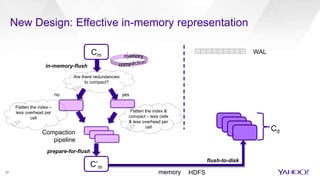
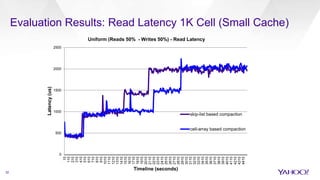
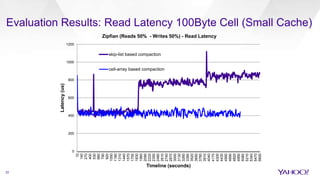
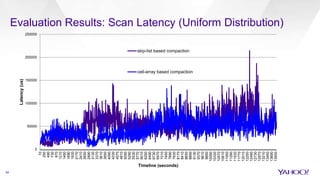



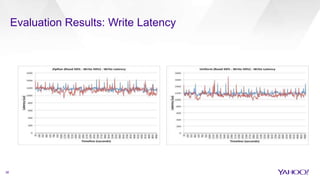
The document discusses enhancements to HBase aimed at improving performance for real-time content processing by implementing in-memory compaction and index reduction techniques. These approaches minimize disk I/O and retrieval latencies by reducing the memory footprint of indices and eliminating redundant data in memory. It evaluates the effectiveness of these designs through experiments, demonstrating significant improvements in latency and resource utilization.























































































