
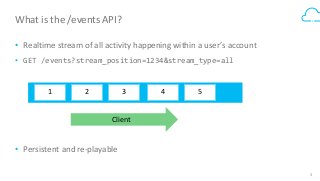
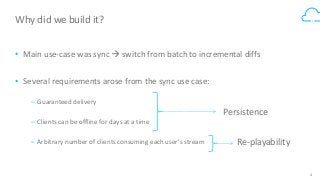

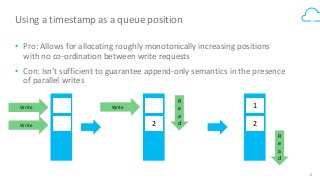

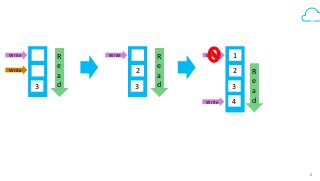
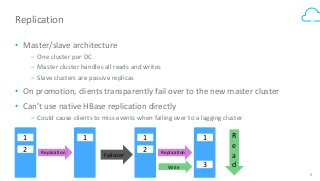
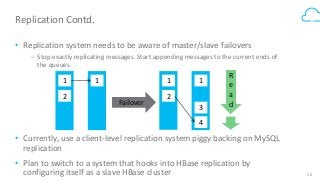




Box's /events API powers our desktop sync experience and provides users with a realtime, guaranteed-delivery event stream. To do that, we use HBase to store and serve a separate message queue for each of 30+ million users. Learn how we implemented queue semantics, were able to replicate our queues between clusters to enable transparent client failover, and why we chose to build a queueing system on top of HBase.















































