

![Data Storage Challenges
• Many HBase apps tend to solve similar problems with common needs
• Developers rebuild these solutions on their own, sometimes repeated for each app
• Effective schema (row key) design is hard
• byte[] conversions, no real native types
• No composite keys
• Some efforts - Orderly library and HBase types (HBASE-8089) - but nothing complete](https://image.slidesharecdn.com/dev-session6-150605171307-lva1-app6891/85/HBaseCon-2015-Reusable-Data-Access-Patterns-with-CDAP-Datasets-3-320.jpg?cb=1433524873)


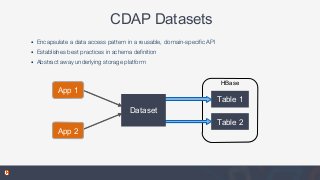



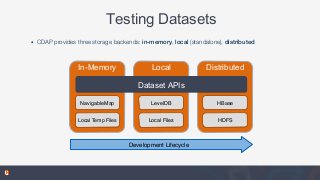







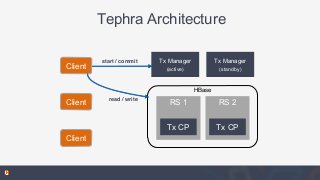










In this talk, you'll learn about Datasets, part of the open source Cask Data Application Platform (CDAP), which provide reusable implementations of common data access patterns. We will also look at how Datasets provide a set of common services that extend the capabilities of HBase: global transactions for multi-row or multi-table updates, read-less increments for write-optimized counters, and support for combined batch and real-time access.















































