

![ Cellify read path HBASE-7320 , HBASE-11871 , HBASE-11805
Cells flow in read path
Move out of KeyValue assumption
HFile block backed by ByteBuffer rather than byte[]
Remove all byte[] assumption in seeking, encoding etc
Cell extension
Support ByteBuffer backed getXXX APIs.
Added Cell extension ByteBufferedCell and exposed within Server only
Creating off heap backed ByteBufferedCell when reading blocks from off heap bucket cache
getXXXArray() calls on off heap buffer backed Cells works with a temp byte[] copy. More garbage
CellUtil APIs for operations like equals, copy which checks for ByteBufferedCell
Suggest CPs, custom filter use these APIs.
Note
Filter# filterRowKey(byte[] buffer, int offset, int length) deprecated against filterRowKey(Cell firstRowCell)
RegionObserver # postScannerFilterRow(ObserverContext<RegionCoprocessorEnvironment>, InternalScanner,
byte[], int, short, boolean) deprecated against
postScannerFilterRow(ObserverContext<RegionCoprocessorEnvironment>, InternalScanner, Cell, boolean)
Building Blocks for Off Heaping](https://image.slidesharecdn.com/devsession5intel-160802225318/85/Off-heaping-the-Apache-HBase-Read-Path-6-320.jpg)
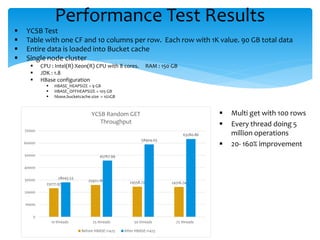
![ KVComparator -> CellComparator HBASE-10800 , HBASE-13500
JMH benchmark with off heap buffer compare vs byte[] compare
Using Unsafe way of compare
Each buffer with 135 bytes
Both buffers equal
No performance overhead with comparing off heap backed cells
Benchmark Mode Cnt Score Error Units
offheapCompare: thrpt 38205893.545 ± 265309.769 ops/s
onheapCompare: thrpt 37166847.740 ± 430242.970 ops/s
Building Blocks for Off Heaping](https://image.slidesharecdn.com/devsession5intel-160802225318/85/Off-heaping-the-Apache-HBase-Read-Path-7-320.jpg)

![ BucketCache evicts blocks and frees the buckets when out of space
Any block can be evicted. Readers copy block data to temp byte[]
After HBASE-11425 readers refer to bucket memory area directly
Can evict only unreferenced blocks
Bucket Cache Block Eviction
Call#setResponse
RpcCallback#run
RegionScanner#shipped
KeyValueHeap#shipped
StoreScanner#shipped
KeyValueHeap#shipped
StoreFileScanner#shipped
HFileScanner#shipped
HFile.Reader#returnBlock
BlockCache#returnBlock Decrement ref count
Ref count based block cache and block eviction
Increment ref count when reader hits a block in L2 cache
Decrement once response is created for RPC
Evict if/when ref count = 0](https://image.slidesharecdn.com/devsession5intel-160802225318/85/Off-heaping-the-Apache-HBase-Read-Path-9-320.jpg)

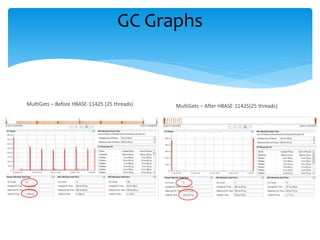
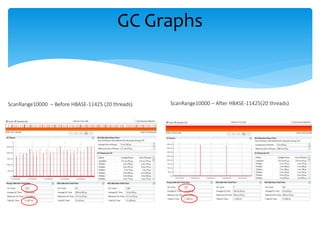


The document discusses enhancements to the HBase read path, particularly focusing on off-heap caching strategies to improve performance by storing data in large, physical memory buffers. It includes benchmark results comparing off-heap and on-heap data access methods, indicating significant performance improvements in read operations with off-heap caching. Future work is outlined, emphasizing advancements in off-heap write paths and buffer management for further optimization.























































































