


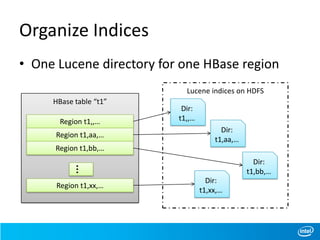


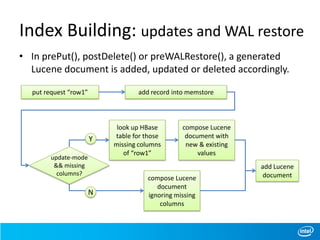
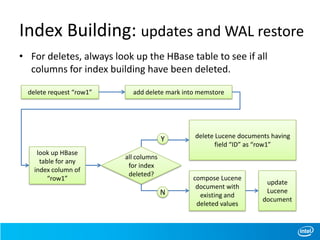
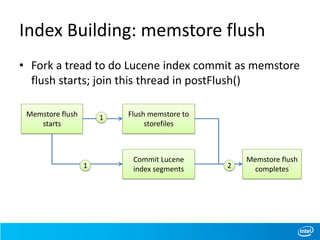


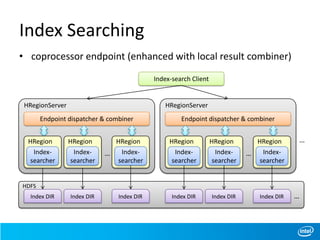
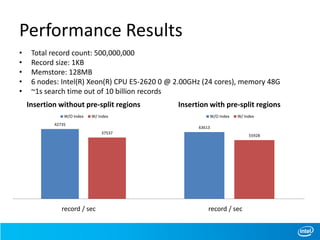
This document discusses full-text indexing for HBase tables. It describes how Lucene indices are organized based on HBase regions. Index building is implemented using coprocessors to update indices on data changes. Index splitting is optimized to avoid blocking updates during region splits. Search performance of indexing 10 billion records was tested, showing search times of around 1 second.











































































































