




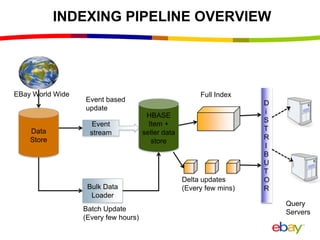


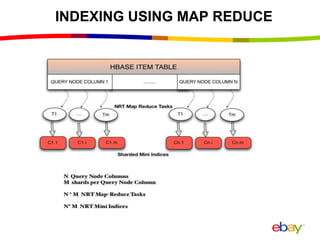
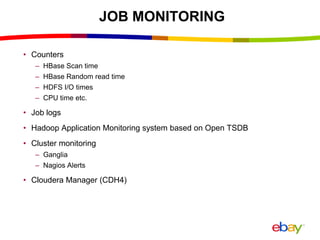
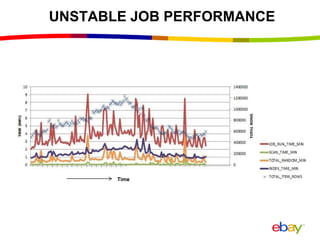


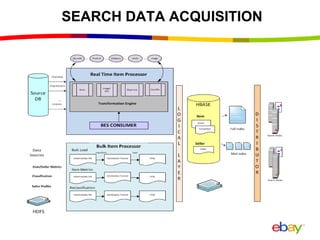
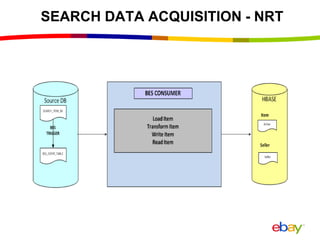




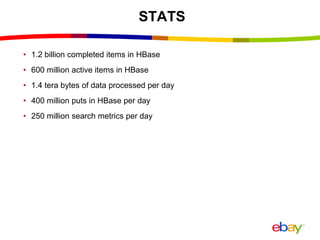

Near Real Time Indexing for ebay Search The document discusses eBay's near real time indexing pipeline to build indexes for search within minutes of data updates. It outlines the challenges of handling a large volume of updates at scale and describes optimizations made to HBase and the indexing process to reduce indexing time and improve stability. These include improved HBase configuration, major compaction scheduling, and standalone indexing to reduce overhead.











































































































