
Abstract
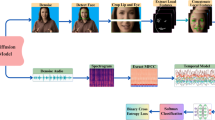
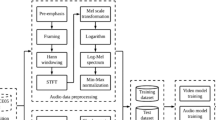
Capturing complex temporal relationships between video and audio modalities is vital for Audio-Visual Emotion Recognition (AVER). However, existing methods lack attention to local details, such as facial state changes between video frames, which can reduce the discriminability of features and thus lower recognition accuracy. In this paper, we propose a Detail-Enhanced Intra- and Inter-modal Interaction network (DE-III) for AVER, incorporating several novel aspects. We introduce optical flow information to enrich video representations with texture details that better capture facial state changes. A fusion module integrates the optical flow estimation with the corresponding video frames to enhance the representation of facial texture variations. We also design attentive intra- and inter-modal feature enhancement modules to further improve the richness and discriminability of video and audio representations. A detailed quantitative evaluation shows that our proposed model outperforms all existing methods on three benchmark datasets for both concrete and continuous emotion recognition. To encourage further research and ensure replicability, our project code is public available at https://github.com/stonewalking/DE-III.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Acheampong, F.A., Nunoo-Mensah, H., Chen, W.: Transformer models for text-based emotion detection: a review of bert-based approaches. Artif. Intell. Rev. 54(8), 5789–5829 (2021)
Ben, X., Ren, Y., Zhang, J., Wang, S.J., Kpalma, K., Meng, W., Liu, Y.J.: Video-based facial micro-expression analysis: A survey of datasets, features and algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 44(9), 5826–5846 (2021)
Busso, C., Parthasarathy, S., Burmania, A., AbdelWahab, M., Sadoughi, N., Provost, E.M.: MSP-IMPROV: An acted corpus of dyadic interactions to study emotion perception. Trans. Affect. Comput. 8(1), 67–80 (2016)
Cao, H., Cooper, D.G., Keutmann, M.K., Gur, R.C., Nenkova, A., Verma, R.: CREMA-D: Crowd-sourced emotional multimodal actors dataset. Trans. Affect. Comput. 5(4), 377–390 (2014)
Cao, Q., Shen, L., Xie, W., Parkhi, O.M., Zisserman, A.: VGGFace2: A dataset for recognising faces across pose and age. In: International Conference on Automatic Face and Gesture Recognition (2018)
Chorowski, J.K., Bahdanau, D., Serdyuk, D., Cho, K., Bengio, Y.: Attention-based models for speech recognition. NeurIPS 28 (2015)
Chudasama, V., Kar, P., Gudmalwar, A., Shah, N., Wasnik, P., Onoe, N.: M2fnet: Multi-modal fusion network for emotion recognition in conversation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4652–4661 (2022)
Chumachenko, K., Iosifidis, A., Gabbouj, M.: Self-attention fusion for audiovisual emotion recognition with incomplete data. In: ICPR. pp. 2822–2828. IEEE (2022)
Deng, J., Ren, F.: A survey of textual emotion recognition and its challenges. IEEE Trans. Affect. Comput. 14(1), 49–67 (2021)
Ge, X., Jose, J.M., Wang, P., Iyer, A., Liu, X., Han, H.: Algrnet: Multi-relational adaptive facial action unit modelling for face representation and relevant recognitions. Behavior, and Identity Science, IEEE Transactions on Biometrics (2023)
Ge, X., Jose, J.M., Xu, S., Liu, X., Han, H.: Mgrr-net: Multi-level graph relational reasoning network for facial action unit detection. ACM Transactions on Intelligent Systems and Technology 15(3), 1–20 (2024)
Ge, X., Wan, P., Han, H., Jose, J.M., Ji, Z., Wu, Z., Liu, X.: Local global relational network for facial action units recognition. In: FG. pp. 01–08. IEEE (2021)
Goncalves, L., Busso, C.: AuxFormer: Robust approach to audiovisual emotion recognition. In: ICASSP. pp. 7357–7361. IEEE (2022)
Goncalves, L., Busso, C.: Learning cross-modal audiovisual representations with ladder networks for emotion recognition. In: ICASSP. pp. 1–5. IEEE (2023)
Goncalves, L., Leem, S.G., Lin, W.C., Sisman, B., Busso, C.: Versatile audio-visual learning for handling single and multi modalities in emotion regression and classification tasks. arXiv preprint arXiv:2305.07216 (2023)
Gong, Y., Liu, A.H., Rouditchenko, A., Glass, J.: Uavm: Towards unifying audio and visual models. IEEE Signal Process. Lett. 29, 2437–2441 (2022)
Gulati, A., Qin, J., Chiu, C.C., Parmar, N., Zhang, Y., Yu, J., Han, W., Wang, S., Zhang, Z., Wu, Y., et al.: Conformer: Convolution-augmented transformer for speech recognition. In: ICASSP. p. 5749–5753. IEEE (2021)
Hsu, W.N., Sriram, A., Baevski, A., Likhomanenko, T., Xu, Q., Pratap, V., Kahn, J., Lee, A., Collobert, R., Synnaeve, G., et al.: Robust wav2vec 2.0: Analyzing domain shift in self-supervised pre-training. arXiv preprint arXiv:2104.01027 (2021)
Hu, M., Ge, P., Wang, X., Lin, H., Ren, F.: A spatio-temporal integrated model based on local and global features for video expression recognition. The Visual Computer pp. 1–18 (2021)
Jaegle, A., Borgeaud, S., Alayrac, J.B., Doersch, C., Ionescu, C., Ding, D., Koppula, S., Zoran, D., Brock, A., Shelhamer, E., et al.: Perceiver IO: A general architecture for structured inputs & outputs. arXiv preprint arXiv:2107.14795 (2021)
Kemmou, A., El Makrani, A., El Azami, I., Aabidi, M.H.: Automatic facial expression recognition under partial occlusion based on motion reconstruction using a denoising autoencoder. Indonesian Journal of Electrical Engineering and Computer Science 34(1), 276–289 (2024)
Li, X., Zhang, Y., Tiwari, P., Song, D., Hu, B., Yang, M., Zhao, Z., Kumar, N., Marttinen, P.: Eeg based emotion recognition: A tutorial and review. ACM Comput. Surv. 55(4), 1–57 (2022)
Livingstone, S.R., Russo, F.A.: The Ryerson audio-visual database of emotional speech and song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 13(5), e0196391 (2018)
Ma, F., Zhang, W., Li, Y., Huang, S.L., Zhang, L.: An end-to-end learning approach for multimodal emotion recognition: Extracting common and private information. In: ICME. pp. 1144–1149 (2019)
Maji, B., Swain, M., Guha, R., Routray, A.: Multimodal emotion recognition based on deep temporal features using cross-modal transformer and self-attention. In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2023)
Mittal, T., Bhattacharya, U., Chandra, R., Bera, A., Manocha, D.: M3er: Multiplicative multimodal emotion recognition using facial, textual, and speech cues. In: Proceedings of the AAAI conference on artificial intelligence. vol. 34, pp. 1359–1367 (2020)
Mittal, T., Guhan, P., Bhattacharya, U., Chandra, R., Bera, A., Manocha, D.: Emoticon: Context-aware multimodal emotion recognition using frege’s principle. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14234–14243 (2020)
Nie, W., Ren, M., Nie, J., Zhao, S.: C-GCN: Correlation based graph convolutional network for audio-video emotion recognition. IEEE Trans. Multimedia 23, 3793–3804 (2020)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
Perveen, N., Roy, D., Chalavadi, K.M.: Facial expression recognition in videos using dynamic kernels. Trans. Image Process. 29, 8316–8325 (2020)
Ruan, D., Yan, Y., Lai, S., Chai, Z., Shen, C., Wang, H.: Feature decomposition and reconstruction learning for effective facial expression recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7660–7669 (2021)
Savchenko, A.V.: Facial expression and attributes recognition based on multi-task learning of lightweight neural networks. In: SISY. pp. 119–124. IEEE (2021)
Shrivastava, K., Kumar, S., Jain, D.K.: An effective approach for emotion detection in multimedia text data using sequence based convolutional neural network. Multimedia tools and applications 78, 29607–29639 (2019)
Spezialetti, M., Placidi, G., Rossi, S.: Emotion recognition for human-robot interaction: Recent advances and future perspectives. Frontiers in Robotics and AI 7 (2020). 10.3389/frobt.2020.532279
Tarantino, L., Garner, P.N., Lazaridis, A., et al.: Self-attention for speech emotion recognition. In: Interspeech. pp. 2578–2582 (2019)
Tsai, Y.H.H., Bai, S., Liang, P.P., Kolter, J.Z., Morency, L.P., Salakhutdinov, R.: Multimodal transformer for unaligned multimodal language sequences. In: ACL. vol. 2019, p. 6558. NIH Public Access (2019)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. NeurIPS 30 (2017)
Wang, K., Peng, X., Yang, J., Lu, S., Qiao, Y.: Suppressing uncertainties for large-scale facial expression recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6897–6906 (2020)
Wang, M.: Micro-expression recognition based on multi-scale attention fusion. In: ICDSCA. pp. 853–861. IEEE (2021)
Wang, X., Kou, L., Sugumaran, V., Luo, X., Zhang, H.: Emotion correlation mining through deep learning models on natural language text. IEEE transactions on cybernetics 51(9), 4400–4413 (2020)
Yin, Y., Jing, L., Huang, F., Yang, G., Wang, Z.: Msa-gcn: Multiscale adaptive graph convolution network for gait emotion recognition. Pattern Recognition p. 110117 (2023)
Zhang, Y., Wang, H., Xu, Y., Mao, X., Xu, T., Zhao, S., Chen, E.: Adaptive graph attention network with temporal fusion for micro-expressions recognition. In: ICME. pp. 1391–1396. IEEE (2023)
Zhang, Y., Wang, C., Deng, W.: Relative uncertainty learning for facial expression recognition. Adv. Neural. Inf. Process. Syst. 34, 17616–17627 (2021)
Zhou, H., Meng, D., Zhang, Y., Peng, X., Du, J., Wang, K., Qiao, Y.: Exploring emotion features and fusion strategies for audio-video emotion recognition. In: ICMI. pp. 562–566 (2019)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Shi, T., Ge, X., Jose, J.M., Pugeault, N., Henderson, P. (2025). Detail-Enhanced Intra- and Inter-modal Interaction for Audio-Visual Emotion Recognition. In: Antonacopoulos, A., Chaudhuri, S., Chellappa, R., Liu, CL., Bhattacharya, S., Pal, U. (eds) Pattern Recognition. ICPR 2024. Lecture Notes in Computer Science, vol 15321. Springer, Cham. https://doi.org/10.1007/978-3-031-78305-0_29
Download citation
DOI: https://doi.org/10.1007/978-3-031-78305-0_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-78304-3
Online ISBN: 978-3-031-78305-0
eBook Packages: Computer ScienceComputer Science (R0)Springer Nature Proceedings Computer Science
