Kafka Isn’t a Database, But We Gave It a Query Engine AnywayBy Simon Chaffetz and Sami Tabet, Software Engineers, WarpStreamMar 20Mar 20
Audit Logs for WarpStream: Full Visibility Into Every Action on Your ClustersBy Jason Lauritzen, Sr. Product Marketing Manager, and Caleb Grillo, Head of ProductFeb 13Feb 13
The Art of Being Lazy(log): Lower latency and Higher Availability With Delayed SequencingBy Manu Cupcic, Sr. Manager, Engineering, and Yusuf Birader, Sr. Software Engineer, WarpStreamFeb 4Feb 4
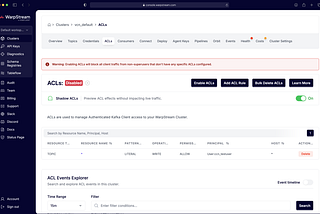
Shadowing Kafka ACLs: A Safer Path to AuthorizationBy Yusuf Birader, Software Engineer, WarpStreamDec 17, 2025Dec 17, 2025
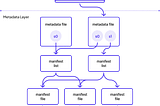
What React and Apache Iceberg Have in Common: Scaling Iceberg with Virtual MetadataBy Richard Artoul, Co-Founder, WarpStreamDec 12, 2025Dec 12, 2025
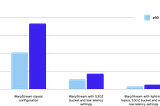
Robinhood Swaps Kafka for WarpStream to Tame Logging Workloads and CostsBy Robinhood + Jason LauritzenDec 9, 2025Dec 9, 2025
Going All in on Protobuf With Schema Registry and TableflowBy Maud Gautier, Software Engineer, WarpStreamDec 3, 2025Dec 3, 2025
How Superwall Uses WarpStream and ClickHouse Cloud to Scale Subscription MonetizationThis engineering blog is reproduced with permission from ClickHouse and Superwall.Oct 10, 2025Oct 10, 2025
The Case for an Iceberg-Native Database: Why Spark Jobs and Zero-Copy Kafka Won’t Cut ItBy Richard Artoul, Co-Founder, WarpStreamSep 30, 2025A response icon1Sep 30, 2025A response icon1
The Road to 100PiBs and Hundreds of Thousands of Partitions: Goldsky Case StudyBy Richard Artoul, Co-Founder, WarpStreamSep 29, 2025Sep 29, 2025