Network configuration is a quite rapidly evolving area which went through multiple phases. It’s also surprisingly tied to monitoring. Below is some historical context from the industry as well as what we’re doing in SRE.
Some context
The past
As there was no standardized or programmatic way to get data in or out of network devices, engineers had to be creative. The early ages of network automation consisted of scripts pretending to be a human operator.
Those scripts would connect to devices (using ssh or telnet) send commands, expecting some prompts and scrapping whatever was sent back.
You can imagine that this was extremely slow and error prone. Output layout would change from one version to the other, unexpected output would break scripts, CLIs would get overwhelmed by too much information entered at once, data would not get validated beforehand.
SNMP
SNMP is a protocol aimed at improving the this situation. Despite the limitations it’s widely disparaged for, SNMP is still widely used to monitor devices, especially as it’s supported on virtually all devices.
It got popular for monitoring as none of its limitations are hard blockers to simply pull counters and states from a device. Security is not critical as it's read only, if a packet doesn’t arrive, it’s not a big deal, data will show up at the next pull.
It’s another story for the configuration aspect. Security is critical (v3 got implemented quite late), being sure that a change got applied as well. These factors, as well as a difficult syntax to interact with, meant it never got wide adoption.
$ /usr/bin/snmpget -v2c -c <secret> -OUQn -m SNMPv2-MIB <hostname> sysDescr.0 .1.3.6.1.2.1.1.1.0 = Juniper Networks, Inc. qfx5100-48s-6q (...)
SNMP, in short:
- Transport: UDP (packet size limited and subject to packet loss)
- Atomicity: None (each request is independent and can change 1 configuration option)
- Message encoding: ASN.1 (quite complex to manually craft)
- Data model: SMI (standard or vendor specific)
- Mostly pull based (SNMP traps are less used, especially as its UDP)
- Encryption:
- v2c: clear text “community” (not secure, most common for “get”)
- v3: authentication and payload encryption (mostly used for “set” if used at all)
The present
Monitoring
We actively use SNMP for monitoring. Mostly through LibreNMS which is fully built around SNMP and provides a great UI which solves one difficult part of monitoring: how to display relevant information. And to a lesser extent with ad-hoc Icinga scripts pulling specific SNMP OIDs (values) for alerting only.
The current system is working fine (and on all our platforms, even PDUs).
Newer protocols have been implemented with features answering modern needs, like more frequent polling (some SNMP implementation discourage pulling data too often), or the ability to get virtually any metric from the devices. In addition to being more reliable.
So if we have to spend engineering time (for example to monitor QoS accurately - T326322), SNMP based tools might not be the best investment.
Regarding configuration, two combining elements played in our favor. First, using exclusively Juniper equipment allowed us to focus our efforts. Second, Juniper was a pioneer in NETCONF based device configuration as well as being “API first”.
NETCONF
NETCONF is in some way the 2nd attempt of the industry for a standardized way of configuring devices. It works in a more layered approach leveraging proven protocols. It is now the industry standard and has been extended in multiple ways.
- Transport: SSH (most common), HTTPS (more recent)
- Encryption: handled by the transport layer
- Message encoding: XML-RPC (most common), JSON-RPC (more recent)
- Data model: YANG* or proprietary via an abstraction layer (eg. Junos set)
- Supports locks, atomic changes (apply a set of changes or nothing), full configuration changes
(*More on YANG later)
<?xml version="1.0" encoding="UTF-8"?> <nc:rpc xmlns:nc="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="urn:uuid:xxx"> <load-configuration format="text" action="replace"> <configuration-text> My configuration </configuration-text> </load-configuration> </nc:rpc> ]]>]]> <rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:junos="http://xml.juniper.net/junos/21.2R0/junos" xmlns:nc="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="urn:uuid:f9ab59d9-746f-423f-b534-67197941f3df"> <load-configuration-results> <rpc-error> <error-severity>warning</error-severity> <error-path>[edit routing-options validation]</error-path> <error-message>mgd: statement has no contents; ignored</error-message> <error-info> <bad-element>static</bad-element> </error-info> </rpc-error> <ok/> </load-configuration-results> </rpc-reply> <?xml version="1.0" encoding="UTF-8"?><nc:rpc xmlns:nc="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="urn:uuid:cc664f8c-8815-41f8-82a8-c655bc6eda10"><get-configuration compare="rollback" rollback="0" format="text"/></nc:rpc>]]>]]> <rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:junos="http://xml.juniper.net/junos/21.2R0/junos" xmlns:nc="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="urn:uuid:cc664f8c-8815-41f8-82a8-c655bc6eda10"> <configuration-information> <configuration-output> </configuration-output> </configuration-information> </rpc-reply>
Our current network automation (Homer) leverages NETCONF through multiple abstraction layers. It fetches data from a couple sources of truth (Netbox and YAML files). Using Jinja templates it formats this data in the most user readable structure (the standard Junos syntax). Last, Juniper’s py-junos-eznc library wraps the generated configuration and overall instructions in XML to send it “over” NETCONF (using ncclient) to the device. Then the device's configuration engine takes care of showing us diffs of what changed, handling rollback, etc.
We’ve opted to do full configuration replacement instead of specific sections only to prevent drifts between devices configurations and wanted state (eg. manual configuration. A Homer “run” will normalize any changes to match the state from our sources of truth. The downside to this approach is its slowness.
To remediate this slowness, we have implemented a more ad-hoc way of doing scope limited changes. For example for server ports configuration. Using Cumin, Cookbooks can send Netbox based configuration changes as well as get states by issuing Junos CLI commands over SSH. This path is made possible by Junos CLI allowing it to return any command output as JSON or XML.
Those tools allowed us to clean-up/streamline our network configuration, remove toil, iterate faster on provisioning, troubleshooting, fix miss-configurations, and react efficiently to attacks at the cost of duplicating some of our automation tooling.
Nevertheless there is still plenty of room for improvement, in the tools itself (T250415: Homer: add parallelization support, performance improvements) the workflows, the configuration standardization and verification, integration with other tools or platforms (T328747: Improve Homer output when Juniper device rejects config. T253194: Homer CI: verify Junos syntax)
The future
We recently started looking at alternate vendors for our network switches. After thorough evaluation we have decided to start rolling out some SONiC based network devices in our production environment (we could call it phase 2 testing) to make sure larger deployments would be doable.
Even though designed with some level of multi-vendor support in mind, only one vendor was implemented in Homer on day one. Which makes it a mostly Junos tool.
During the evaluation we had to make sure that any alternate vendor would either be automated either in a similar way as we’re currently doing (full configuration replacement + ad-hoc cli commands) or in a way that goes in the same direction as the whole industry (including Juniper). The former being a quick way to get started but is risky in the long run. The latter has a larger upfront engineering cost but is an investment on the future. Despite the drawback of not supporting NETCONF, SONiC falls in the 2nd category.
Extensive documentation on its management framework is available online (being open source probably helps).
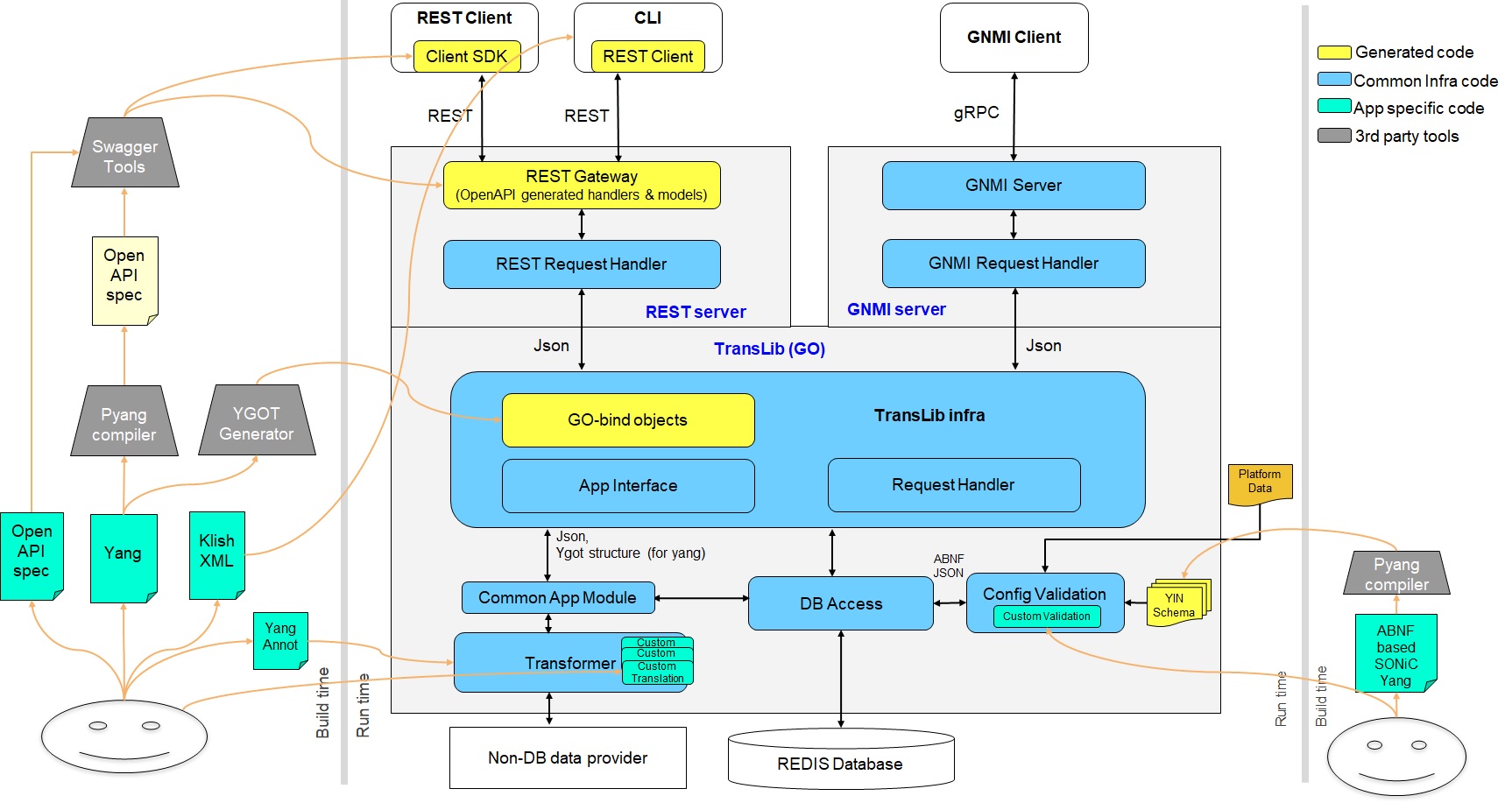
Source: https://github.com/sonic-net/SONiC/blob/master/doc/mgmt/images/Mgmt_Frmk_Arch.jpg
On this diagram we can see that there are 2 programmatic ways to interact with a device: REST(CONF) and gNMI. The CLI becomes a regular REST client, the same goes for Junos.
Quick digression on Datastores
Before being formally called datastores, most network devices had the concept of “2 or more configuration’s versions”. We can think of Cisco’s historic startup vs. running configuration or Juniper’s more modern configuration history. In 2018 RFC8342 standardize and extends those 3 base datastores:
- Startup: optional, rw, persistent
- Candidate: optional, rw, volatile, can be messed with, no production impact
- Running: required, rw, persistent
With:
- Intended: required, ro, volatile, can be same as running, apply any needed transformations
- Operational: ro, all configuration and states data
+-------------+ +-----------+
| <candidate> | | <startup> |
| (ct, rw) |<---+ +--->| (ct, rw) |
+-------------+ | | +-----------+
| | | |
| +-----------+ |
+-------->| <running> |<--------+
| (ct, rw) |
+-----------+
|
| // configuration transformations,
| // e.g., removal of nodes marked as
| // "inactive", expansion of
| // templates
v
+------------+
| <intended> | // subject to validation
| (ct, ro) |
+------------+
| // changes applied, subject to
| // local factors, e.g., missing
| // resources, delays
|
dynamic | +-------- learned configuration
configuration | +-------- system configuration
datastores -----+ | +-------- default configuration
| | |
v v v
+---------------+
| <operational> | <-- system state
| (ct + cf, ro) |
+---------------+
ct = config true; cf = config false
rw = read-write; ro = read-only
boxes denote named datastoresIt’s up to the upper protocols (RESTCONF, NETCONF, etc) to define ways to expose or copy between those datastores (commit, rollback, etc).
RESTCONF
This more recent protocol RFC 8040 (2017) can be imagined as a NETCONF over HTTPS, leveraging the now popular REST architecture. Due to its younger age, it has less features but is regularly extended. For example RFC 8527 (March 2019) paves the way for config rollback style operations (there is only a non-standard implementation so far) as well as subscriptions (itself in RFC 8650) by bringing the concept of datastores to RESTCONF.
RESTCONF, in short:
- Transport: HTTPS
- Encryption: handled by the transport layer (TLS)
- Message encoding: XML or JSON
- Data model: YANG*
- Python libraries: many options, starting by the well known Python's Requests
(*More on YANG later)
gNMI
While NETCONF and RESTCONF were getting popular for network configuration, SNMP was still the only real option to get monitoring data from network devices. Despite NETCONF (RFC 5277) and RESTCONF (RFC 8650) being extended to support push/notifications the former never took off, and the latter is still too young to tell.
Streaming telemetry (also called push, subscribe, notification) is a feature aimed at replacing SNMP on the monitoring side. Instead of regularly polling a device like SNMP based monitoring does, a client subscribes to specific items/data on the device. Through a long lived client/server session, the device will send updated metrics when needed. Some examples on why it’s better than SNMP in this NANOG presentation.
gNMI (gRPC Network Management Interface), built by Google on top of gRPC, is getting some traction in the industry for that purpose mostly due to its speed compared to the alternatives. That said, gNMI also supports regular “get” and “set” methods as defined in its specification document (there is no RFC). It also got further extended to support operational commands (restart, clear neighbors, manage certs, etc) through what’s called gNOI (gRPC Network Operations Interface).
gNMI, in short:
- Transport: gRPC (HTTP/2)
- Encryption: handled by the transport layer (TLS)
- Message encoding: JSON, Protobuf
- Data model: YANG*
- Supports atomic changes (apply a set of changes or nothing, also called transactions)
(*More on YANG later)
gNMI being a Google creation, most libraries and tools revolving around this protocol are written in Go. The client library, the standalone client tools and the swiss army knife (gNMIc). If there is a single tool to learn, it's gNMIc as it can do pretty much everything gNMI related and much more.
The Python ecosystem on the other hand is fairly dire. First any project needs to convert the gNMI protobuf specs into Python libraries or using the pre-made one available from upstream, managing multiple versions of the spec could potentially be a challenge.
- pygnmi seems the most interesting as it’s feature rich and actively-ish developed. gNOI is however not supported.
- python-gnmi-proto (hasn't been updated since 2021) takes a different approach, different grpc library, less abstraction (let the user handle the gRPC calls directly)
As gNMI is multi-platform, we can also look at various vendor’s PoC, with the risk of them becoming platform specific in the future.
- Arista’s gnmi-py doesn’t support the “set” operations
- Cisco’s cisco-gnmi-python seems feature rich as well.
$ gnmic -a lsw1-e8-eqiad.mgmt.eqiad.wmnet:8080 --username admin --password Wikimedia capabilities gNMI version: 0.7.0 supported models: [...] # Mix of OpenConfig and SONiC specific YANG models supported encodings: - JSON - JSON_IETF - PROTO
from pygnmi.client import gNMIclient host = ('lsw1-e8-eqiad.mgmt.eqiad.wmnet', '8080') with gNMIclient(target=host, username='admin', password='Wikimedia', debug=True) as gc: result = gc.capabilities() print(result)
YANG
YANG is a standardized (RFC 7950) way to structure both configuration and operational (metrics) information, a bit like a DB schema. Similar to SMI it’s possible to define dependencies between modules (like SNMP MIBs), forming a tree. Even though the data model structure is standardized, there are both vendor specific and vendor agnostic modules. Many of those models are available on the YangModels Github. The OpenConfig are the most notable vendor neutral models, but it’s of course up to the vendors to support them.
At least Dell's SONiC aims at supporting OpenConfig. However using a mix of vendor-generic and vedor-specific models is often required to fully manage a given device as OpenConfig only covers common features.
+--rw system +--rw ntp +--rw config | +--rw enabled? boolean | +--rw ntp-source-address? oc-inet:ip-address | +--rw enable-ntp-auth? boolean | +--rw trusted-key* uint16 | +--rw source-interface* oc-if:base-interface-ref | +--rw network-instance? -> /oc-ni:network-instances/network-instance/name +--rw ntp-keys | +--rw ntp-key* [key-id] | +--rw key-id -> ../config/key-id | +--rw config | | +--rw key-id? uint16 | | +--rw key-type? identityref | | +--rw key-value? string | | +--rw encrypted? boolean +--rw servers +--rw server* [address] +--rw address -> ../config/address +--rw config | +--rw address? oc-inet:host | +--rw port? oc-inet:port-number | +--rw version? uint8 | +--rw association-type? enumeration | +--rw iburst? boolean | +--rw prefer? boolean | +--rw key-id? uint16 | +--rw minpoll? uint8 | +--rw maxpoll? uint8
One important aspect is how to efficiently use those data models in our Python based automation world. Manually crafting Python structures to match the expected formats didn't seem appealing to me, even though that's how at least some other (Aerleon, Salt, Ansible) do it.
One direction I investigated is the possibility to create Python bindings from YANG models, which would allow us to manipulate data as Python objects. The hope is for example to abstract type checking, dataset comparison, IDE auto-completion.
- Pyangbind, plugin for pyang,
abandoned(maybe coming back to life?) - Cisco’s YDK is actively maintained but complex to setup, furthermore it requires the whole SDK to be included in any application that want to use those bindings
- For RESTCONF OpenAPI servers (built based on YANG data) it’s possible to use openapi-python-client and in some way reverse-engineer the YANG models… not optimal
- Pyang-pydantic, another pyang plugin to generate pydantic models from YANG models.
- pydantify (relevant paper), more recent but experimental. Still the most promising option yet too young for my use-cases
- In addition to using it as a configuration builder, it could potentially also be used as a syntax checker or a way of showing differences between two configurations (eg. candidate and running)
Much easier in Go, where tools exist to convert such models directly to Go bindings or Protobuf schemas. But wait! It’s possible to convert gNMI Protobuf schemas to Python objects. A way that I didn't explore at the risk of being too convoluted for our use cases.
The plan
Now that we have an overview of the modern and less modern ways of interacting with network devices, here is the current plan.
NETCONF vs. gNMI
To start with, we need something that works with both Juniper and SONiC to try to hope for "one protocol to rule them all". Thus, NETCONF is out of the game as not supported by SONiC.
RESTCONF's main advantage is its easier handling (as based on HTTP). On the other hand, gNMI is a faster and a “two in one” solution as it handles both monitoring and configuration.
After testing both, gNMI seems the best bet forward to me as its only downside (apparent opacity) is counterbalanced by good tools and libraries (gnmic, grpcio).
It is unlikely that one or the other becomes obsolete anytime soon, and even though as long as the data models don't (YANG), the required modifications to go from one transport to the other would only mean switching tools (easier said than done, but much better than changing data models). gNMI is also supported by all major vendors (Cisco, Arista, etc) so we don't get vendor lock-in by using it.
Authentication
One thing that is sure though, is that both RESTCONF and gNMI require a good PKI infrastructure as they both require TLS. T334594: TLS certificates for network devices is the first building block for our next-gen automation.
Then comes authentication. Until now we have done everything over SSH, both for CLI and NETCONF. Unfortunately RESTCONF and gNMI both require a TLS based authentication mechanism.
While SONiC supports both basic HTTP (regular username/password) and client certificate (username in the certificate's CN field), Junos only supports basic HTTP (certificate is only an additional layer of security, but doesn't authenticate the user itself). Which means that we have to implement a mechanism to define passwords to at least users that will use the API (eg. Homer).
On top of that, SONiC's support of users through the API is still limited (doesn't handle SSH keys, doesn't expose hashed-passwords).
For both of those reasons, T338028: Users management on SONiC is the next critical stepping stone to tackle, multiple paths and proposals are being discussed in the task.
Automation
Only now comes the important part of the topic, our automation.
Even though gNMI might make Homer fast enough to obsolete some of the network related cookbook the workflow of each tools are distinct enough to not make it a short term goal. Keeping both tools separated will also help making the transition easier. This will of course bring the risk of duplicated code, like we currently have for Juniper.
The low number of options make the choice of Python library easier: pyGNMI does the job well.
Unfortunately the various YANG to Python bindings libraries are not ripe enough for prime time, which means we will have to rely on Python dictionaries structures. Those are not that bad once we're familiar with them, but we should keep an eye on Pydantify (especially the Pydantic 2 upgrade).
Once we have the data-structures, we need to be able to compare them. So far this process was offloaded to Juniper's OS. Send the new data, ask for a diff, commit if fine. This is not strictly needed for simple actions, like configuring a single switch interface, but the more complex the change, the more needed it is to catch mistakes before it's too late. A basic implementation could rely on existing libraries such as dictdiff or deepdiff, but also on the pyGNNMI diff_openconfig feature once some of the bugs have been fixed (see my couple PRs and somes issues) .
Cookbooks
An initial proof of concept approach is available on Gerrit CR924896 it shows that it works fine but a few things are needed to be production grade quality:
- T340045: Package pyGNMI and dictdiffer to be used by cookbooks
- Migrate the OpenConfig/gNMI cookbook functions to Spicerack (not needed on day 1)
- Implement a diff feature as mentioned above
Homer
The initial scaffolding to support gNMI has been done (see CR927736). Some adjustments are needed but its logic has been validated.
One point not cleared up yet, is how to run it from our own laptops. The current Homer/Junos/NETCONF leverages SSH and thus is able to automatically use our jump-hosts. HTTP's equivalent is Socks5 (see for example T319426: [cookbooks] Add ssh socks5 proxy support) but its support in gRPC is unlikely to happen anytime soon (see https://github.com/grpc/grpc/issues/30347)
Next steps are to iterate to add support for various SONiC configuration elements one after the other. The easiest approach is to manually configure a device, fetch its configuration on the OpenConfig format, then "templatize" it. Which is the approach we took when working on Juniper devices. Starting with the easy bits. Re-using the diff feature.
While this goal progresses, we will benefit from transitioning more data from YAML files to Netbox, thanks to T336275: Upgrade Netbox to 4.x and T305126: Make more extensive use of Netbox custom fields.
The last special bit is Capirca Aerleon. The ACL generation library. Despite claiming to support OpenConfig ACLs, some features are missing and the output format doesn't fit the OpenConfig YANG model. My pull requests to fix that are either merged or being reviewed (#311, #312, #313).
Monitoring
Still an area to explore, and less urgent for us. gNMIc as a Prometheus intermediary is a promising option.
Conclusion
This is not an easy path, but the way forward is relatively clear at this point. More issues will undoubtedly show up as we progress. Achieving this goal will bring 3 key benefits:
- Unified (and modern!) protocol for configuration and monitoring
- Multi-vendors support
- Faster operations
Illustration photo by Benjamin Elliott on Unsplash



{kind=link}
{kind=link}