Blog


Democratizing AI Compute Series
Go behind the scenes of the AI industry with Chris Lattner
Latest


TileTensor Part 1 - Safer, More Efficient GPU Kernels
Suppose you want to load a 2D tile of a matrix, where the tile is stored in shared memory in a specific interleaved layout to avoid bank conflicts. This example uses a toy XOR swizzle to illustrate the class of bugs; real kernels use hardware- and layout-specific swizzles and vectorized accesses. Without a layout abstraction, here is how you would launch a kernel with a block size of (32,8):


Structured Mojo Kernels Part 4 - Portability and the Road Ahead
GPU portability has a mixed track record. “Write once, run everywhere” usually means “write once, run slowly everywhere.” CUTLASS does not attempt portability beyond NVIDIA hardware and is usually limited within a generation of the hardware. Triton provides portability but performance degrades on non-NVIDIA targets. The conventional wisdom is that you have to choose between being portable or being fast.

Modverse #54: From GTC to Edinburgh, a Community Building Momentum
This edition covers one of the busiest stretches in Modular's recent history: four days at GTC, a new office on another continent, fresh community builds, and a release that expands what MAX and Mojo🔥 can do. Here's everything that's been happening across the ecosystem.

Software Pipelining for GPU Kernels: Part 1 - The Pipeline Problem
Flash Attention is a simple algorithm: tiled back-to-back matmuls with an online softmax algorithm in between. The algorithm fits in a few dozen lines of pseudocode. Yet Flash Attention 4's production kernel is 2,875 lines, and the hardest part to get right isn't the math. It's the async execution and pipelining synchronization, all hand-derived from a schedule that no standard debugging tool can verify.

Structured Mojo Kernels Part 3 - Composition in Practice
This post shows the practical benefit of this modular design. We take two real kernel families, conv2d and block-scaled matmul, and trace exactly how they are built around the matmul foundation. In both cases, a new kernel family requires changing one component while leaving the rest untouched. The conv2d kernel adds roughly 130 lines of new code, whileBlock-scaled matmul adds roughly 200 with no performance degradation.
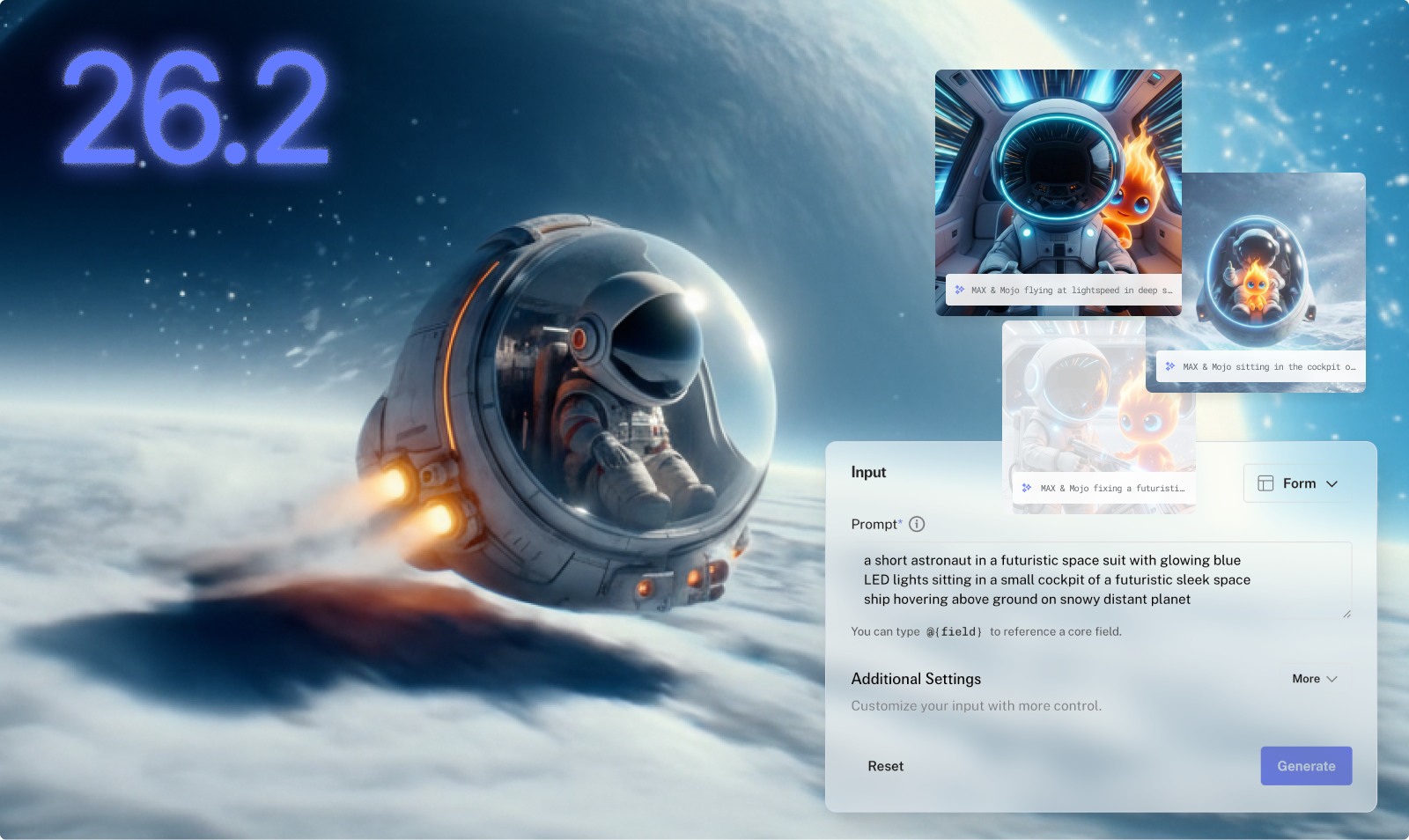
Modular 26.2: State-of-the-Art Image Generation and Upgraded AI Coding with Mojo
Today’s 26.2 release expands the Modular Platform’s modality support to include image generation and image editing workflows. This extends our existing support for text and audio generation. In the 26.2 version Black Forest Labs' FLUX.2 model variants are supported with over a 4x speedup over state-of-the-art.

No items found within this category
We couldn’t find anything. Try changing or resetting your filters.

Sign up today
Signup to our Cloud Platform today to get started easily.
Sign Up
Browse open models
Browse our model catalog, or deploy your own custom model
Browse models