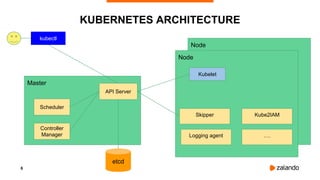
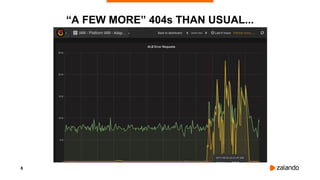
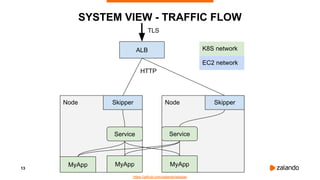
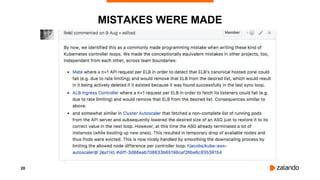
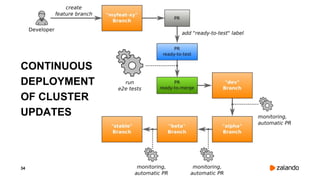
The document discusses challenges and fallacies encountered in distributed computing using Kubernetes on AWS, particularly focusing on API server failures impacting system availability. It outlines specific mistakes made and how they were rectified, as well as the importance of resilience and testing methodologies such as chaos testing. The document emphasizes learning from failures and establishing a healthy post-mortem culture within engineering teams.