Download as PDF, PPTX











![21
INCIDENT #2: RTFM
% etcdctl del -r /registry-kube-1/certificatesigningrequest prefix
help: etcdctl del [options] <key> [range_end]](https://image.slidesharecdn.com/2018-12-05runningkubernetesinproductionamillionwaystocrashyourcluster-devopsconmunich-181205161537/85/Running-Kubernetes-in-Production-A-Million-Ways-to-Crash-Your-Cluster-DevOpsCon-Munich-2018-21-320.jpg)




![27
INCIDENT #3: STOP THE BLEEDING
#!/bin/bash
SLEEPTIME=60
while true; do
echo "sleep for $SLEEPTIME seconds"
sleep $SLEEPTIME
timeout 5 curl http://localhost:8080/api/v1/nodes > /dev/null
if [ $? -eq 0 ]; then
echo "all fine, no need to restart etcd member"
continue
else
echo "restarting etcd-member"
systemctl restart etcd-member
fi
done](https://image.slidesharecdn.com/2018-12-05runningkubernetesinproductionamillionwaystocrashyourcluster-devopsconmunich-181205161537/85/Running-Kubernetes-in-Production-A-Million-Ways-to-Crash-Your-Cluster-DevOpsCon-Munich-2018-27-320.jpg)
![28
INCIDENT #3: CONFIRMATION FROM AWS
[...]
We can’t go into the details [...] that resulted the networking problems during
the “non-intrusive maintenance”, as it relates to internal workings of EC2.
We can confirm this only affected the T2 instance types, ...
[...]
We don’t explicitly recommend against running production services on T2
[...]](https://image.slidesharecdn.com/2018-12-05runningkubernetesinproductionamillionwaystocrashyourcluster-devopsconmunich-181205161537/85/Running-Kubernetes-in-Production-A-Million-Ways-to-Crash-Your-Cluster-DevOpsCon-Munich-2018-28-320.jpg)




![41
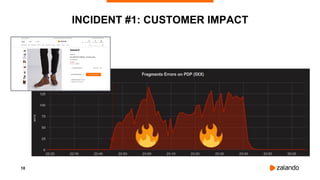
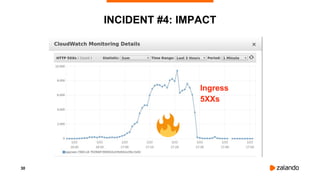
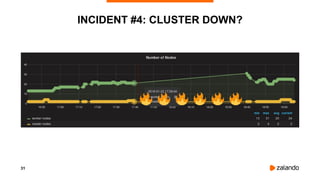
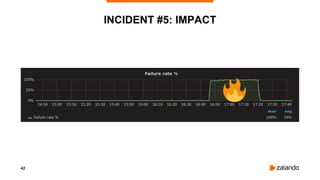
INCIDENT #5: IMPACT
[4:59 PM] Marc: There is a error during build - forbidden: image policy webhook backend denied
one or more images: X-Trusted header "false" for image pierone../ci/cdp-builder:234 ..
[5:01 PM] Alice: Now it does not start the build step at all
[5:02 PM] John: +1
[5:02 PM] John: Failed to create builder pod: …
[5:02 PM] Pedro: +1
[5:04 PM] Damien: +1
[5:19 PM] Anton: We're currently having issues pulling images from our Docker registry which
results in many problems…
...](https://image.slidesharecdn.com/2018-12-05runningkubernetesinproductionamillionwaystocrashyourcluster-devopsconmunich-181205161537/85/Running-Kubernetes-in-Production-A-Million-Ways-to-Crash-Your-Cluster-DevOpsCon-Munich-2018-41-320.jpg)


![46
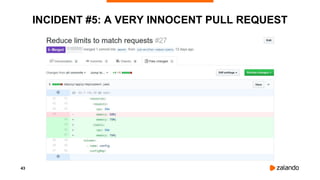
INCIDENT #6: CREDENTIALS QUEUE
17:30:07 | [pool-6-thread-1 ] | Current queue size: 7115, current number of active workers: 20
17:31:07 | [pool-6-thread-1 ] | Current queue size: 7505, current number of active workers: 20
17:32:07 | [pool-6-thread-1 ] | Current queue size: 7886, current number of active workers: 20
..
17:37:07 | [pool-6-thread-1 ] | Current queue size: 9686, current number of active workers: 20
..
17:44:07 | [pool-6-thread-1 ] | Current queue size: 11976, current number of active workers: 20
..
19:16:07 | [pool-6-thread-1 ] | Current queue size: 58381, current number of active workers: 20](https://image.slidesharecdn.com/2018-12-05runningkubernetesinproductionamillionwaystocrashyourcluster-devopsconmunich-181205161537/85/Running-Kubernetes-in-Production-A-Million-Ways-to-Crash-Your-Cluster-DevOpsCon-Munich-2018-46-320.jpg)
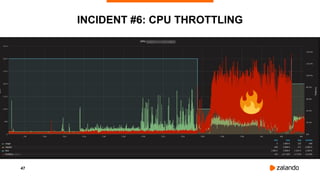


![50
DISABLING CPU THROTTLING
[Announcement] CPU limits will be disabled
⇒ Ingress Latency Improvements
kubelet … --cpu-cfs-quota=false](https://image.slidesharecdn.com/2018-12-05runningkubernetesinproductionamillionwaystocrashyourcluster-devopsconmunich-181205161537/85/Running-Kubernetes-in-Production-A-Million-Ways-to-Crash-Your-Cluster-DevOpsCon-Munich-2018-50-320.jpg)









This document summarizes Henning Jacobs' talk on running Kubernetes in production and the many ways clusters can crash. It describes several incidents Zalando faced with their Kubernetes clusters that led to outages, including API server issues causing ingress problems, etcd deletion causing cluster downtime, EC2 networking issues, image pulling failures, and credential processing bottlenecks preventing deployments. Each incident highlighted lessons around disaster recovery planning, automated testing of upgrades, monitoring cloud infrastructure, and avoiding resource starvation.

































![[k8s] Kubernetes terminology (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/k8skubernetesterminology1-230513211357-e2d31a79-thumbnail.jpg?width=640&height=640&fit=bounds)













































