Downloaded 81 times



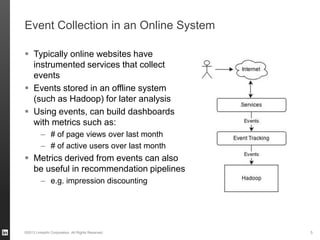

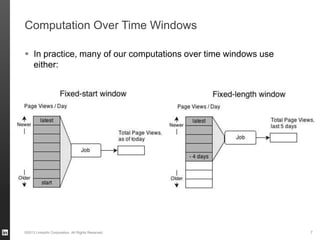
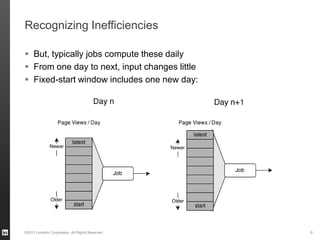
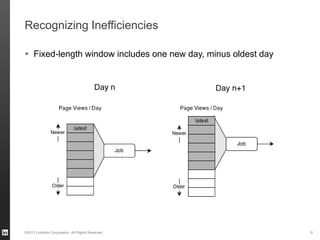



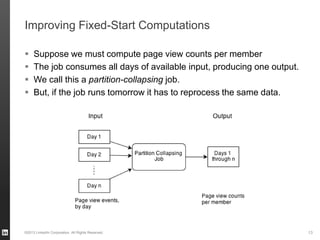
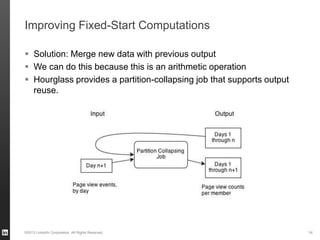
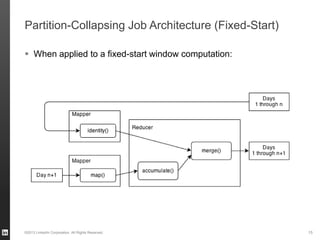
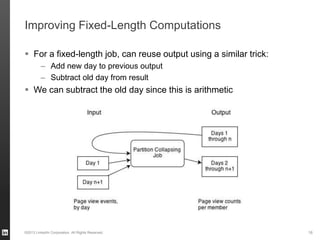
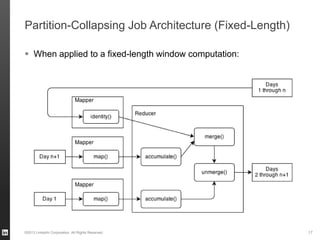
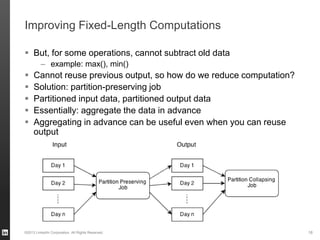
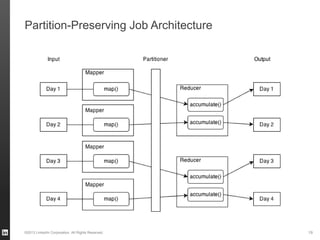
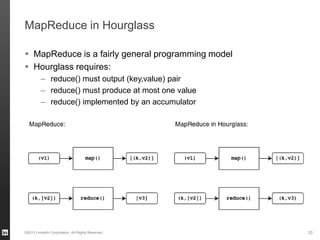



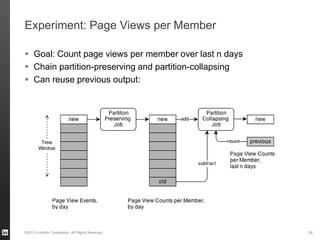
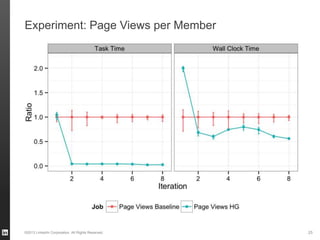
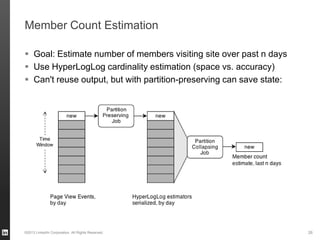
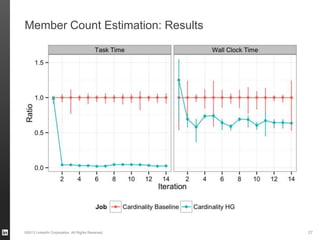


The document discusses Hourglass, a library designed for incremental processing on Hadoop, highlighting its ability to efficiently handle computations over time windows. It offers solutions to common inefficiencies in data processing, enabling output reuse for fixed-start and fixed-length computations, which significantly reduce resource usage and processing time. Experimental results indicate that incrementalizing Hadoop jobs can lead to substantial reductions in both total task time and wall clock time.























































































